PI 5 · MOVENET + SEGFORMER · 35 CLASSES
Wearable navigation aid on a Raspberry Pi 5 — MoveNet + SegFormer over a custom 35-class dataset. Two 1st-place track wins at HackAI 2026.
- RESULT
- 1st place · 2 tracks · HackAI 2026
- TRACKS
- IEEE + TI (combined) · Google Antigravity
- TEAM
- Rafael Amador · Leonardo Santos
- STACK
- Pi 5 · MoveNet · SegFormer · GPIO haptics
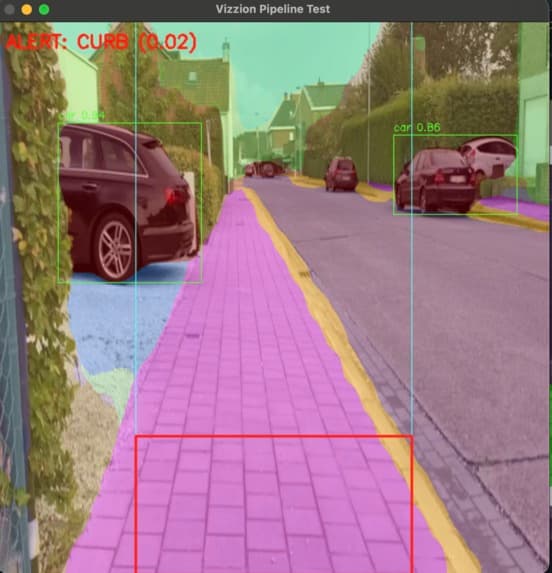
Vizzion is a 24-hour HackAI 2026 build — a wearable obstacle-detection system for visually impaired users that runs live computer vision on a Raspberry Pi 5 and communicates hazards through differentiated buzzer patterns. MoveNet Multipose detects people in real time; a SegFormer model fine-tuned on a custom 35-class navigation dataset (curbs, stairs, potholes, signs, poles, vehicles…) classifies the rest of the scene. A priority encoder maps detections to vibration patterns — slow pulses for static obstacles, rapid for vehicles, long buzz for ground-level drops — so the wearer feels the world before walking into it. Built with Leonardo Santos. 1st place in both tracks entered: the combined IEEE + Texas Instruments track and the Google Antigravity track.
The white cane only reports what its tip touches — nothing past arm’s length, impact-only detection in crowds, and no semantics. Vizzion adds a perception layer: detection before contact, different buzzes for different hazards, and ~5 m of effective range.
Camera → two parallel models → one priority queue → a dedicated vibration thread → GPIO PWM buzzer. Three decisions worth flagging from 24 hours of build time:
| DECISION | WHY IT MATTERS |
|---|---|
| Two models, one priority queue | MoveNet handles people; SegFormer handles everything else — a single ranker picks the most urgent hazard per frame, so the user never gets competing buzz patterns |
| Vibration on its own thread | Sleeping in the main loop to time a pulse drops frames — the detection loop fires events; the vibration thread owns all motor state |
| Priority cooldown (~1.5 s per class) | A person standing in frame doesn't buzz the user continuously |

The original plan was MobileNet SSD v2 on the Pi CPU — fast, single download. The shipped version swapped in two specialized models: MoveNet is pose-aware — not just “person there” but which way they face and move — and SegFormer’s per-pixel labels turn the feed into a semantic map rather than boxes. Cityscapes’ class set targets autonomous driving, so the team built a custom 35-class dataset in Roboflow and fine-tuned NVIDIA’s checkpoint via Hugging Face — adding curbs, stairs, potholes, and pedestrian-relevant classes Cityscapes doesn’t separate.
The trade: slower per-frame than SSD, dramatically richer output — the difference between “it can detect a person” and “it can describe the scene.” The swap was cheap because the inference layer was abstracted from day one (detector_base.py).
IEEE + Texas Instruments (one combined track): judged on rigorous engineering, ethical impact, embedded work, and hardware-software integration — Vizzion’s spread covered all of it: multi-model CV pipeline, transistor-driver circuit with GPIO PWM, accessibility mission, working hardware demo.
Google Antigravity: MoveNet — a Google model — handled the highest-priority class, and the Antigravity platform was the build’s development environment. The model choice paid twice: accuracy on people, and direct alignment with the track.
The sprint itself was phased like an engineering project, not a hackathon scramble: hardware bring-up by hour 3, end-to-end pipeline with a 10-minute soak test by hour 12, demo rehearsed three times from cold boot, and a backup demo video recorded before the buffer window closed.
